Halaman ini menjelaskan menjalankan komputasi Python dengan environment Anaconda di ALELEON Supercomputer.

Langkah Menjalankan Komputasi
Terdapat dua langkah utama:
- Membuat dan menyiapkan conda environment untuk komputasi user.
- Memilih metode menjalankan komputasi.
Membuat Conda Environment
Kegiatan ini dilakukan pada terminal:
- Diakses melalui login SSH, atau
- Pada web EFIRO, buka menu Clusters -> Aleleon Shell Access
| Membuat Conda Environment
|
| 1
|
Pilih dan aktifkan modul Anaconda yang akan digunakan.
$ module load [nama-modul-anaconda]
|
| Daftar nama modul Anaconda
|
| Nama Modul
|
Versi
|
| Anaconda3/2023.07-2
|
Anaconda 3 2023.07-2
|
| Anaconda3/2022.05
|
Anaconda 3 2022.05
|
| Anaconda3/2021.05
|
Anaconda 3 2021.05
|
| Anaconda3/2020.11
|
Anaconda 3 2020.11
|
|
| 2
|
Buat conda env di direktori HOME dan aktifkan dengan perintah:
$ conda create --name [nama-conda-env] pip
Contoh nama 'skripsi'
$ conda create --name skripsi pip
|
| Mengaktifkan Conda Environment dan Instalasi Package
|
| 0
|
Aktifkan modul Anaconda yang digunakan untuk membuat conda env user.
|
| 1
|
Aktifkan conda env dengan perintah:
$ source activate [nama-conda-env]
Contoh mengaktifkan conda env 'skripsi'
$ source activate skripsi
|
| User dapat melihat daftar conda env yang dibuat sebelumnya dengan:
$ conda env list
|
| 2
|
Lakukan instalasi package Python yang dibutuhkan dengan pip
|
| 3
|
Untuk menonaktifkan conda env jalankan perintah:
$ conda deactivate
|
| Manajemen Conda Environment
|
| 1
|
Deactivate conda env untuk melakukan manajemen dibawah ini.
|
| 2
|
Untuk mengubah nama conda env:
$ conda rename -n [nama-saat-ini] [nama-baru]
Contoh mengubah nama env skripsi ke tesis
$ conda rename -n skripsi tesis
|
| Untuk menghapus conda env:
$ conda remove -n <nama-conda-env> --all
|
Metode Menjalankan Komputasi
User dapat memilih metode menjalankan komputasi sesuai keinginan:
- Job submission di terminal
- Job submission di web EFIRO
- Interactive job Jupyter Lab / Notebook
Job Submission Terminal
Ketentuan:
- Menjalankan file Python di terminal dengan scheduler SLURM.
- File ipynb harus dikonversi ke file Python.
- Berjalan di Compute Node.
- Tutorial ini mengasumsikan user familiar dengan terminal Linux.
| Langkah Job Submission Terminal
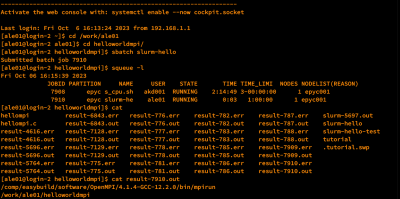
|
| 1
|
Login SSH ke ALELEON Supercomputer.
|
| 2
|
Siapkan conda env dan file komputasi yang dibutuhkan.
|
| 3
|
Buat Submit Script yaitu 'formulir' untuk menjalankan job komputasi.
- Nama file bebas dengan format .sh, contoh
submit.sh
|
Contoh template Submit Script, ikuti petunjuk NOTES didalamnya.
| Anaconda Python di CPU
|
#!/bin/bash
# -----------------------------------------------------
# Template SLURM Submit Script
# Anaconda Python (CPU)
#
# NOTES:
# 1. Isi bagian yang ditandai 4 garing (////).
# 2. Template ini bersifat referensi.
# User dapat mengubah bagian yang perlu diubah.
# 3. Pastikan user sudah membuat Conda Environment.
# -----------------------------------------------------
# -----------------------------------------------------
# Alokasi komputasi SBATCH dan file input
# -----------------------------------------------------
# Alokasi jumlah core thread CPU
#SBATCH --ntasks=////
# Alokasi jumlah memori RAM (satuan GB)
#SBATCH --mem=////GB
# Alokasi limit waktu menjalankan job
# Format HH:MM:SS atau D-HH:MM:SS
#SBATCH --time=////
# Definisi file untuk menampung output terminal program
#SBATCH --output=result-%j.txt
# Definisi file untuk menampung output error log
#SBATCH --error=error-%j.txt
# Nama Conda Environment yang digunakan
CONDA_NAME=////
# Nama program Python yang dijalankan
INPUT_FILE=////.py
# ----------------------------------------------------
# Script jalannya program
# ----------------------------------------------------
# Mengaktifkan Conda Environment
module load Anaconda3
source activate ${CONDA}/${CONDA_NAME}
# Menjalankan file Python
python3 ${INPUT_FILE}
|
| Anaconda Python di GPU
|
#!/bin/bash
# -----------------------------------------------------
# Template SLURM Submit Script
# Anaconda Python (GPU)
#
# NOTES:
# 1. Isi bagian yang ditandai 4 garing (////).
# 2. Template ini bersifat referensi.
# User dapat mengubah bagian yang perlu diubah.
# 3. Pastikan user sudah membuat Conda Environment.
# -----------------------------------------------------
# -----------------------------------------------------
# Alokasi komputasi SBATCH dan file input
# -----------------------------------------------------
# Menggunakan partisi compute node GPU
#SBATCH --partition=ampere
# Alokasi jumlah core thread CPU
#SBATCH --ntasks=////
# Alokasi jumlah GPU
#SBATCH --gpus=////
# Alokasi jumlah memori RAM (satuan GB)
#SBATCH --mem=////GB
# Alokasi limit waktu menjalankan job
# Format HH:MM:SS atau D-HH:MM:SS
#SBATCH --time=////
# Definisi file untuk menampung output terminal program
#SBATCH --output=result-%j.txt
# Definisi file untuk menampung output error log
#SBATCH --error=error-%j.txt
# Nama Conda Environment yang digunakan
CONDA_NAME=////
# Nama program Python yang dijalankan
INPUT_FILE=////.py
# ----------------------------------------------------
# Script jalannya program
# ----------------------------------------------------
# Memuat modul NVIDIA CUDA default
module load cuda
# Mengaktifkan Conda Environment
module load Anaconda3
source activate ${CONDA}/${CONDA_NAME}
# Menjalankan file Python
python3 ${INPUT_FILE}
|
Info script lebih detail lihat Submit Script ALELEON Supercomputer.
|
| Panduan nilai maksimal alokasi komputasi SBATCH
|
Pada akun perseorangan, SLURM akan menahan job apabila:
- ntasks * time (jam) lebih besar dari sisa CPU Core Hour user
- gpus * time (jam) lebih besar dari sisa GPU Hour user
Cek sisa kredit dengan perintah sausage di terminal.
|
Limitasi fair policy usage untuk menjaga kualitas layanan:
| ntasks
|
mem
|
gpus
|
time
|
| 128
|
128GB
|
2
|
72:00:00
|
User dapat mengajukan permintaan membuka limitasi melalui form ini.
|
Versi CPU:
| Node
|
ntasks
|
mem
|
gpus
|
time
|
| normal
|
128
|
240GB
|
-
|
72:00:00
|
| high-mem*
|
500GB
|
*Tambahkan parameter #SBATCH --nodelist=epyc001
|
Versi GPU:
| ntasks
|
mem
|
gpus
|
time
|
| 32
|
120GB
|
2
|
72:00:00
|
|
Versi MPI (dengan MPI4PY):
| ntasks
|
mem
|
gpus
|
time
|
| 384
|
240GB
|
-
|
72:00:00
|
Ketika ntasks lebih dari 128:
- SLURM otomatis menjalankan job pada multi-node.
- Mem mengalokasikan memori RAM per-node.
- Info detail buka laman MPI ALELEON Supercomputer.
|
|
| 4
|
Jalankan job komputasi dengan perintah:
$ sbatch [nama-submit-script]
Contoh:
$ sbatch submit.sh
|
| 5
|
User dapat melihat status jalannya job dengan perintah:
$ squeue -ul $USER
| Daftar ST (STATE) yang menunjukkan status jalannya job:
|
| STATE
|
Penjelasan
|
| R (RUN)
|
Job berjalan
|
| PD (PENDING)
|
Job tertahan, lihat NODELIST(REASON)
|
| CG (COMPLETING)
|
Job selesai dan dalam proses clean-up
|
| CA (CANCELED)
|
Job dibatalkan user
|
| PR (PREEMPETED)
|
Job dibatalkan admin, alasan dikabarkan via email
|
| S (SUSPENDED)
|
Job ditahan admin, alasan dikabarkan via email
|
|
| 6
|
Apabila user ingin menghentikan job yang berjalan, jalankan perintah:
$ scancel [job-ID]
Job ID ada pada squeue diatas.
contoh membatalkan job ID 231:
$ scancel 231
|
Job Submission Web EFIRO
Ketentuan:
- Menjalankan file Python di web EFIRO Job Composer dengan scheduler SLURM.
- File ipynb harus dikonversi ke file Python.
- Berjalan di Compute Node.
| Langkah Job Submission Web EFIRO
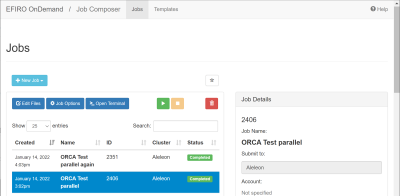
|
| 1
|
Login ke web EFIRO ALELEON Supercomputer.
|
| 2
|
Buka app Job Composer di Pinned Apps.Pilih menu New Job -> From Template
|
| 3
|
Pilih template Anaconda Python yang diinginkan.
| Daftar template Anaconda Python
|
| Nama Template
|
Penjelasan
|
| Anaconda Python (CPU)
|
Menjalankan Anaconda Python versi CPU
|
| Anaconda Python (GPU)
|
Menjalankan Anaconda Python versi GPU
|
Isi Job Name kemudian klik Create New Job
|
| 4
|
Upload dan edit file untuk menjalankan komputasi pada Edit Files Tombol Edit Files dan Open Terminal- Untuk upload file tunggal diatas 2GB gunakan software FTP.
- Apabila butuh akses terminal untuk edit conda env buka
Open Terminal.
|
| 5
|
Lengkapi Submit Script melalui tombol Open Editor.
- Submit script adalah 'formulir' untuk menjalankan job komputasi.
- Ikuti petunjuk NOTES didalamnya
- Klik
Save setiap kali mengubah script.
|
| Panduan nilai maksimal alokasi komputasi SBATCH
|
Pada akun perseorangan, SLURM akan menahan job apabila:
- ntasks * time (jam) lebih besar dari sisa CPU Core Hour user
- gpus * time (jam) lebih besar dari sisa GPU Hour user
Cek sisa kredit dengan perintah sausage di menu Open Terminal
|
Limitasi fair policy usage untuk menjaga kualitas layanan:
| ntasks
|
mem
|
gpus
|
time
|
| 128
|
128GB
|
2
|
72:00:00
|
User dapat mengajukan permintaan membuka limitasi melalui form ini.
|
Versi CPU:
| Node
|
ntasks
|
mem
|
gpus
|
time
|
| normal
|
128
|
240GB
|
-
|
72:00:00
|
| high-mem*
|
500GB
|
*Tambahkan parameter #SBATCH --nodelist=epyc001
|
Versi GPU:
| ntasks
|
mem
|
gpus
|
time
|
| 32
|
120GB
|
2
|
72:00:00
|
|
Versi MPI (dengan MPI4PY):
| ntasks
|
mem
|
gpus
|
time
|
| 384
|
240GB
|
-
|
72:00:00
|
Ketika ntasks lebih dari 128:
- SLURM otomatis menjalankan job pada multi-node.
- Mem mengalokasikan memori RAM per-node.
- Info detail buka laman MPI ALELEON Supercomputer.
|
|
| 6
|
Jalankan job dengan klik tombol Submit. Tombol Submit dan Stop disebelahnya. - Pantau kolom status yang menjelaskan status jalannya job.
- Apabila ingin membatalkan job yang berjalan, klik
Stop.
- User dapat menjalankan kembali job yang completed dengan
Submit.
| Daftar status job
|
| Status
|
Arti
|
| Not Submitted
|
Job belum pernah dijalankan.
|
| Running
|
Job berjalan.
|
| Queue
|
Job mengantri dan belum berjalan.
|
| Completed
|
Job selesai berjalan.
|
| Failed
|
Job berhenti di tengah jalan, antara error atau di stop user
|
Untuk melihat alasan queue:
- Buka app
Active Jobs pada homepage EFIRO.
|
|
| 7
|
User dapat melihat output file komputasi pada kolom Folder Contents
- Atau dengan membuka
Edit Files
|
Interactive Job Jupyter
Ketentuan:
- Menjalankan sesi interaktif Jupyter Lab atau Notebook.
- Berjalan di Interactive Node.
| Langkah Interactive Job Sesi Jupyter
|
|
|
|
|
|
|
|
|
|














